Heart Disease Prediction AI
My Role
Data Scientist & ML Engineer – Predictive Pipeline Development
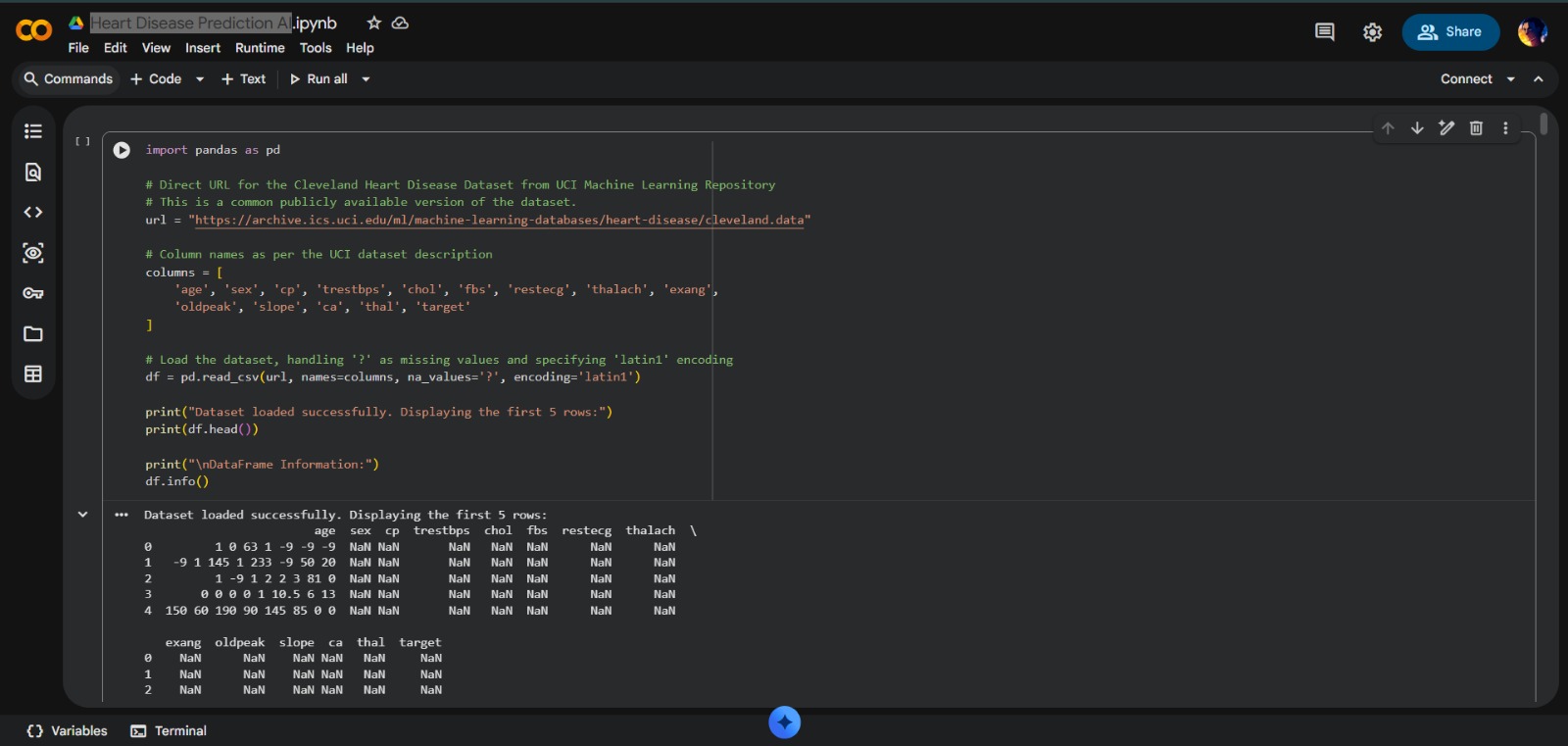
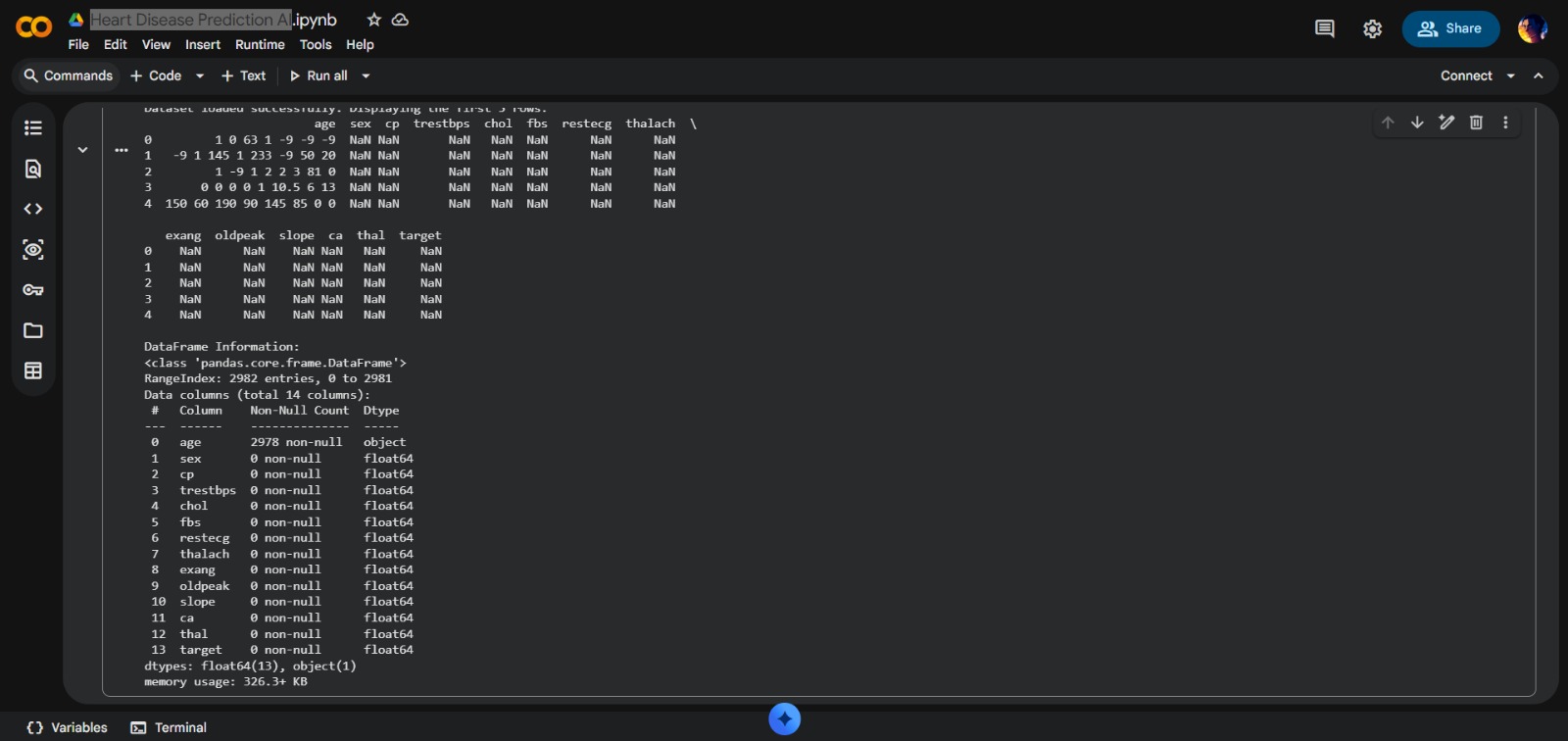
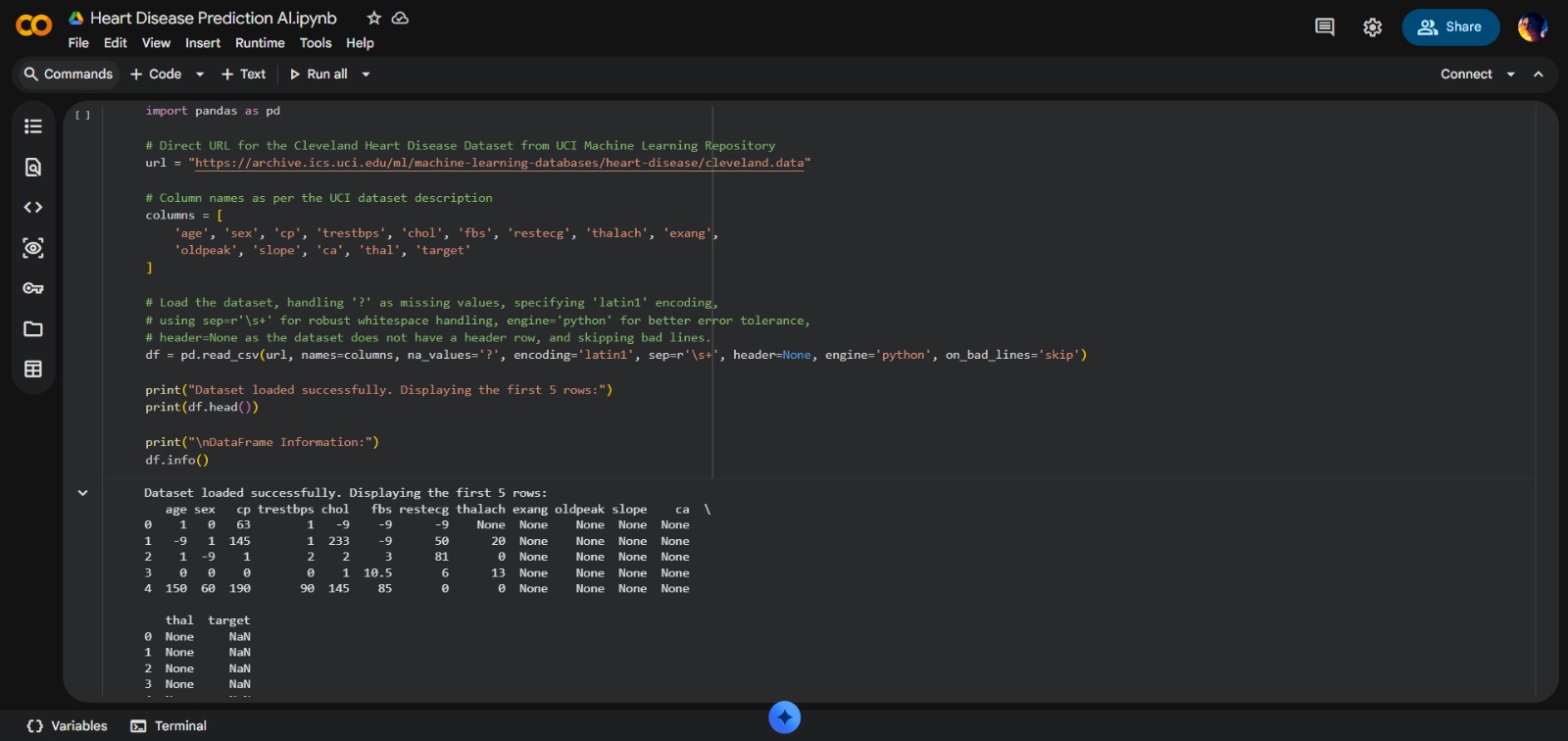
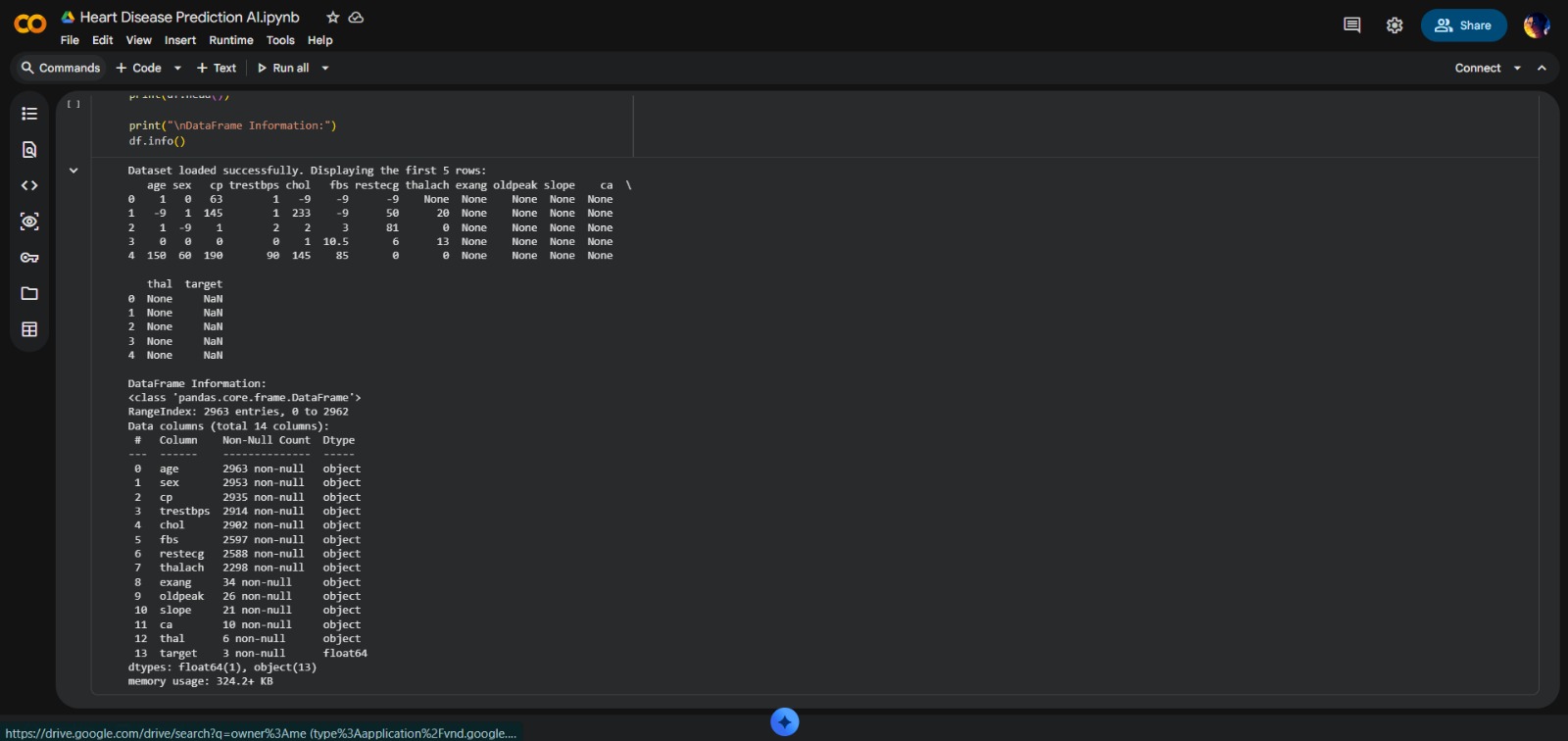
- Advanced Data Cleaning: Engineering multi-stage cleaning using Regex
- Target Variable Engineering: Re-mapping multi-class medical labels into binary classification
- Statistical Imputation: Implementing median-based imputation for missing values
- Feature Engineering: One-Hot Encoding and Standard Scaling implementation
- Model Implementation: Developing and fine-tuning Logistic Regression classifier
Project Highlights
- Real-World Data Handling: Successfully navigated messy clinical dataset with standalone hyphens and invalid patterns
- High-Fidelity Preprocessing: Achieved clean dataset from source with over 70% missing values
- Scalable Workflow: Pipeline designed for easy testing of other models (Random Forests, SVMs)
- Clinical Relevance: Focused on medical features like thalach and chest pain types
- Interpretability-First Design: Selected Logistic Regression for clinician-friendly results